

Java入门系列之hashCode和equals(十二)
前言
前面两节内容我们详细讲解了Hashtable算法和源码分析,针对散列函数始终逃脱不掉hashCode的计算,本节我们将详细分析hashCode和equals,同时您将会看到本节内容是从《Effective Java》学习整理而来(吐槽一句,这本书中文版翻译的真垃圾),对于《Effective Java》这本书很有学习价值,但是我不会像其他童鞋一样,直接从这本书讲解一个系列,我所采用的是学习到对应地方然后参考不同java经典书籍进行总结,循序渐进式这样效果更佳,好了,我们开始吧。
equals
翻看《Effective Java》关于equals这一节内容,直接抛出重写equals必须遵守的如下五大约定,当我看到这几大特性时,顿时惊呆了,这不就是大学线代讲解矩阵时的特点么,学以致用原来是这么个道理。
1、自反性:对于非空的对象x,x.equals(x)必须返回true.
2、对称性:对于非空的对象x和y,若x.equals(y)等于true时,那么y.equals(x)也必须返回true.
3、传递性:对于非空的对象x、y和z,如果x.equals(y)和y.equals(z)等于true时,那么x.equals(z)也必须返回true
4、一致性:对于非空的对象x和y,如果利用equals判断对象的信息没有被修改时,无论调用多少次,那么x.equals(y)要么为true,要么为false
5、对于非空的对象x,x.equals(null)必须返回false
关于第一点很好理解,非空对象自身引用必须相等,对于第二点书中所给的例子则是将重写对象比较某个字符串时不区分大小写,但是字符串对象是区分大小写,如此这样将导致对称不一致问题,对于第三点则是继承时注意equals的传递性,第4点则强调多次调用通过equals判断的恒等性,最后一点更好理解如若不判断则会抛出空指针异常。那么我们实际在重写equals时可将以下几点作为模板来使用就可以啦。
1、使用“==”判断两个对象是否引用相同
2、使用instanceof操作符来检查参数类型是否相同
3、若类型相同,则将参数转换为正确的类型
4、比较对象中每个值是否都相等,若全部相等则返回true,否则为false
如上几点模板来自《Effective Java》对重写equals的总结,当然我们可以从重写字符串对象中的equals找到如上影子,字符串对象的equals方法如下:
public boolean equals(Object anObject) { // 判断对象引用是否相等,相等直接返回 if (this == anObject) { return true; } //判断对象参数类型是否正确 if (anObject instanceof String) { //若参数类型相同,则转换为对应的参数类型 String anotherString = (String)anObject; int n = value.length; //比较参数对象中的所有值是否相等 if (n == anotherString.value.length) { char v1[] = value; char v2[] = anotherString.value; int i = 0; while (n-- != 0) { if (v1[i] != v2[i]) return false; i++; } return true; } } return false; }
好了,到这里我们讲解完了equals,还是比较简单,那么重写equals时为何一定要重写hashCode呢?主要原因在于:这是通用约定,如果是基于散列的集合比较HashMap或者HashSet等,存储对象地址需要通过散列函数计算hashCode,如若不这样做将会出现意想不到的问题。那么意想不到的问题是什么呢?
hashCode
下面我们用一个例子来讲解为何重写equals时一定要重写hashCode。
public class Person { int age; String name; public Person(int age, String name) { this.age = age; this.name = name; } @Override public boolean equals(Object obj) { if (this == obj) { return true; } if (obj instanceof Person) { Person p = (Person) obj; return (this.age == p.age && this.name == p.name); } return false; } }
如上我们给出一个Person对象,然后带有年龄和名称两个属性,重写时判断年龄和名称相等即可认为为同一人,下面我们在控制台进行如下操作,然后我们看看将会打印出什么结果呢。
Person p1 = new Person(12, "Jeffcky"); Person p2 = new Person(12, "Jeffcky"); Hashtable hashtable = new Hashtable(); hashtable.put(p1, "v1"); System.out.println(hashtable.get(p2));

不难理解,因为Hashtable对象存储地址是基于hashCode,但是上述我们没有重写hashCode,所以我们实例化对象p2时,即使重写了equals两个对象相等,结果获取p2的值肯定是获取不到的,因为hashCode不等,接下来我们重写hashCode
@Override public int hashCode() { return (31 * Integer.valueOf(this.age).hashCode() + name.hashCode()); }

我们看到字符串对象重写了hashCode,因为字符串用的很频繁,同时我们极有可能在散列集合中用到。下面我们来看看字符串对象的hashCode实现方式。
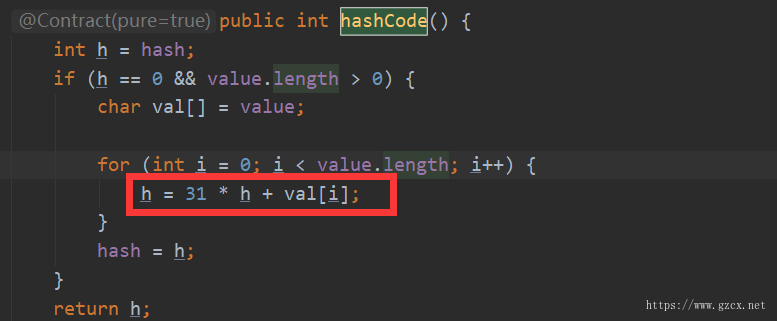
上图标记出的就是计算字符串的hashCode核心即散列函数,从上看出通过字符串中每一个字符的ASCII码来计算,同时我们也可再拓展下看源码数值类型的hashCode就是其本身。上述计算方式最终我们数学进行归纳出计算方法为:
s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
比如我们计算字符串【AC】的hashCode,根据如上计算公式则是
65*31^(2-1) + 67*31^(2-2) = 2082
在《Effective Java》中提到之所以选择31的原因是:它是一个奇素数,如果乘数是偶数,并且乘法溢出的话,信息就会丢失,因为2相乘等价于移位运算。使用素数的好处并不很明显,但是习惯使用素数来计算散列结果。我严重怀疑是不是翻译的人理解错了意思,对于书中给出选择素数的原因无法让人折服,这里我来讲解我个人的想法。
散列函数为什么要使用质数
选择31的原因是因为它是质数(素数),而不是因为它是奇数。当我们插入一个元素到哈希表中时,哈希如何识别需要将元素存储在哪个存储桶中(Bucket)呢?这是一个重要的问题,使得强制性要求哈希能够在恒定时间内告诉我们将值存储在哪个存储桶中,以便能够快速检索。我们能想到的是傻瓜式操作方式即循环遍历比较,这种顺序搜索将直接导致哈希性能恶化,直接取决哈希表所包含值的数量。换句话说,这将具有线性性能成本(O(N)),随着键(N)的数量越来越大,性能可想而知。另一个复杂之处是我们要处理的值的实际类型。若我们要处理字符串和其他复杂类型,检查或比较本身的数量将导致成本又将变得很高。基于以上叙述,所以我们至少需要解决两个问题,其一是便于快速检索而非顺序检索,其二是解决复杂类型值的比较。解决此问题的简单方法是希望出现一种将复杂值分解为易于使用的键或哈希的方法,实现此过程的最简单方法是生成唯一编号,该数字必须是唯一的,因为我们要区分一个值和另一个值。质数是唯一数字,它们的独特之处在于,由于使用了素数来构成素数,因此素数与任何其他数字的乘积具有的最大可能的唯一性(不像素数本身那样唯一),质数的此属性在哈希函数中使用可减少冲突次数(或碰撞)。例如使用4 * 8,则它比诸如3 * 5的质数乘积更有可能发生冲突,32可以通过1 * 32或2 * 16或4 * 8或2 ^ 5等计算得到,但3*5 只能以1 * 15或3 * 5得到15。
总结
本文我们详细讨论了hashCode和equals,以及分析了在散列函数中使用质数的原因,这里还存在一节内容留到学习虚拟机时再补上,通过分析虚拟机源码了解hashCode具体实现,下一节我们将进入学习分析HashMap源码,感谢您的阅读,我们下节见。











