

【原创】杂谈自增主键用完了怎么办
引言
在面试中,大家应该经历过如下场景
面试官:"用过mysql吧,你们是用自增主键还是UUID?"
你:"用的是自增主键"
面试官:"为什么是自增主键?"
你:"因为采用自增主键,数据在物理结构上是顺序存储,性能最好,blabla..."
面试官:"那自增主键达到最大值了,用完了怎么办?"
你:"what,没复习啊!!"
(然后,你就可以回去等通知了!)
这个问题是一个粉丝给我提的,我觉得挺有意(KENG)思(B)!
于是,今天我们就来谈一谈,这个自增主键用完了该怎么办!
正文
简单版
我们先明白一点,在mysql中,Int整型的范围如下
| 类型 | 最小值 | 最大值 | 存储大小 |
|---|---|---|---|
| Int(有符号) | -2147483648 | 2147483648 | 4 bytes |
| Int(无符号) | 0 | 4294967295 | 4 bytes |
我们以无符号整型为例,存储范围为0~4294967295,约43亿!我们先说一下,一旦自增id达到最大值,此时数据继续插入是会报一个主键冲突异常如下所示
//Duplicate entry '4294967295' for key 'PRIMARY'那解决方法也是很简单的,将Int类型改为BigInt类型,BigInt的范围如下
| 类型 | 最小值 | 最大值 | 存储大小 |
|---|---|---|---|
| BigInt(有符号) | -9223372036854775808 | 9223372036854775808 | 8 bytes |
| BigInt(无符号) | 0 | 18446744073709551615 | 8 bytes |
就算你每秒10000条数据,跑100年,单表的数据也才
10000*24*3600*365*100=31536000000000
这数字距离BigInt的上限还差的远,因此你将自增ID设为BigInt类型,你是不用考虑自增ID达到最大值这个问题!
然而,如果你在面试中的回答如果是
你:"简单啊,把自增主键的类型改为BigInt类型就好了!"
接下来,面试官可以问你一个更坑的问题!
面试官:"你在线上怎么修改列的数据类型的?"
你:"what!我还是回等通知吧!"
怎么改
目前业内在线修改表结构的方案,据我了解,一般有如下三种
方式一:使用mysql5.6+提供的在线修改功能
所谓的mysql自己提供的功能也就是mysql自己原生的语句,例如我们要修改原字段名称及类型。
mysql> ALTER TABLE table_name CHANGE old_field_name new_field_name field_type;那么,在mysql5.5这个版本之前,这是通过临时表拷贝的方式实现的。执行ALTER语句后,会新建一个带有新结构的临时表,将原表数据全部拷贝到临 时表,然后Rename,完成创建操作。这个方式过程中,原表是可读的,不可写。但是会消耗一倍的存储空间。
在5.6+开始,mysql支持在线修改数据库表,在修改表的过程中,对绝大部分操作*,原表可读,也可以写。
那么,对于修改列的数据类型这种操作,原表还能写么?来来来,烟哥特意去官网找了mysql8.0版本的一张图
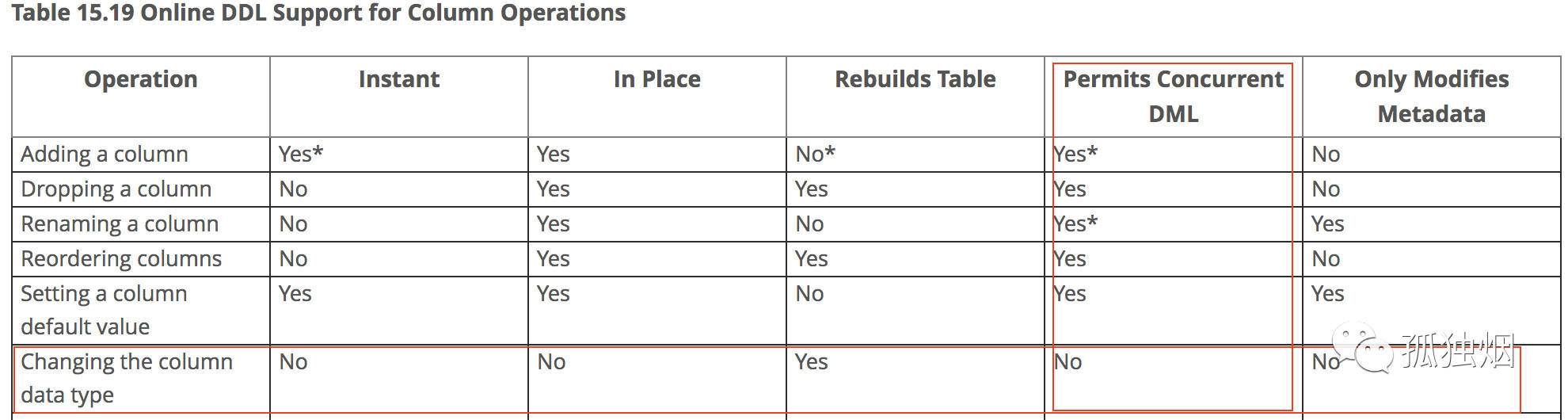
如图所示,对于修改数据类型这种操作,是不支持并发的DML操作!也就是说,如果你直接使用ALTER这样的语句在线修改表数据结构,会导致这张表无法进行更新类操作(DELETE、UPDATE、DELETE)。
因此,直接ALTER是不行滴!
那我们只能用方式二或者方式三
方式二:借助第三方工具
业内有一些第三方工具可以支持在线修改表结构,使用这些第三发工具,能够让你在执行ALTER操作的时候,表不会阻塞!比较出名的有两个
- 1、
pt-online-schema-change,简称pt-osc - 2、GitHub正式宣布以开源的方式发布的工具,名为
gh-ost
以pt-osc为例,它的原理如下
- 1、创建一个新的表,表结构为修改后的数据表,用于从源数据表向新表中导入数据。
- 2、创建触发器,用于记录从拷贝数据开始之后,对源数据表继续进行数据修改的操作记录下来,用于数据拷贝结束后,执行这些操作,保证数据不会丢失。
- 3、拷贝数据,从源数据表中拷贝数据到新表中。
- 4、rename源数据表为old表,把新表rename为源表名,并将old表删除。
- 5、删除触发器。
然而这两个有意(KENG)思(B)的工具,居然。。。居然。。。唉!如果你的表里有触发器和外键,这两个工具是不行滴!
如果真碰上了数据库里有触发器和外键,只能硬杠了,请看方式三
方式三:改从库表结构,然后主从切换
此法极其麻烦,需要专业水平的选手进行操作。因为我们的mysql架构一般是读写分离架构,从机是用来读的。我们直接在从库上进行表结构修改,不会阻塞从库的读操作。改完之后,进行主从切换即可。唯一需要注意的是,主从切换过程中可能会有数据丢失的情况!
高深版
其实答完上面的问题后,这篇文章差不多完了。但是,还记得我在开头说的么。这是一个很有意(KENG)思(B)的问题,为什么呢?
假设啊,你的表里的自增字段为有符号的Int类型的,也就是说,你的字段范围为-2147483648到2147483648。
一切又那么刚好,你的自增ID是从0开始的,也就是说,现在你的可以用的范围为0~2147483648。
我们明确一点,表中真实的数据ID,肯定会出现一些意外,ID不一定是连续的。例如,有如下情形的出现
CREATE TABLE `t` (
`id` int(11) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`id`),
) ENGINE=InnoDB;执行下列SQL
insert into t values(null);
// 插入的行是 (1)
begin;
insert into t values(null);
rolllack;
insert into t values(null);
// 插入的行是 (3)因此,表中的真实id必然会出现断续的情况。
好,那这会你的自增主键id的数据范围为0~2147483648,也就是单表21亿条数据!考虑id会出现断续,真实数据顶多18亿条吧。
老哥,都单表18亿条了,还不分库分表?你一旦分库分表了,就不能依赖于每个表的自增ID来全局唯一标识这些数据了。此时,我们就需要提供一 个全局唯一的ID号生成策略来支持分库分表的环境。因此,你需要关注的文章是《分库分表后如何上线部署》
因此在实际中,你根本等不到自增主键用完到情形!
所以,专业版回答如下
面试官:"那自增主键达到最大值了,用完了怎么办?"
你:"这问题没遇到过,因为自增主键一般用int类型,一般达不到最大值,我们就分库分表了,所以不曾遇见过!"











