

故障处理总纲
1、前言
没有完美的程序,是程序都有bug,都有容量限制。所以出现故障也在情理之中,那么面对突如其来的bug,我们该如何应对呢?这是一个值得思考的问题?
2、核心原则
将正在发生或已发生故障的损害程度减轻到最低-恢复服务
而与之对应的错误做法是成谜于追求破案的情结之中,无法自拔,而这样做的结果往往都是时间过去了,原因没找到,故障进一步升级,这个需要引起重视。
3、排兵布阵
接收到故障告警,我们需要做的几个要素如下:
- 拉群。包含开发、测试、运维。必须有一个故障总负责人,负责全局故障处理统筹
- 初步公告,通知对应的交付顾问,告知现在的状况
4、考虑方向
- 近期是否有上线与之关联的代码 (代码回滚)
- 流量是否正常 (限流、扩容)
- 依赖的三方服务是否正常 (降级)
- 报错是否与业务的异常数据相关 (异常数据处理、过滤)
5、常见的处理方案
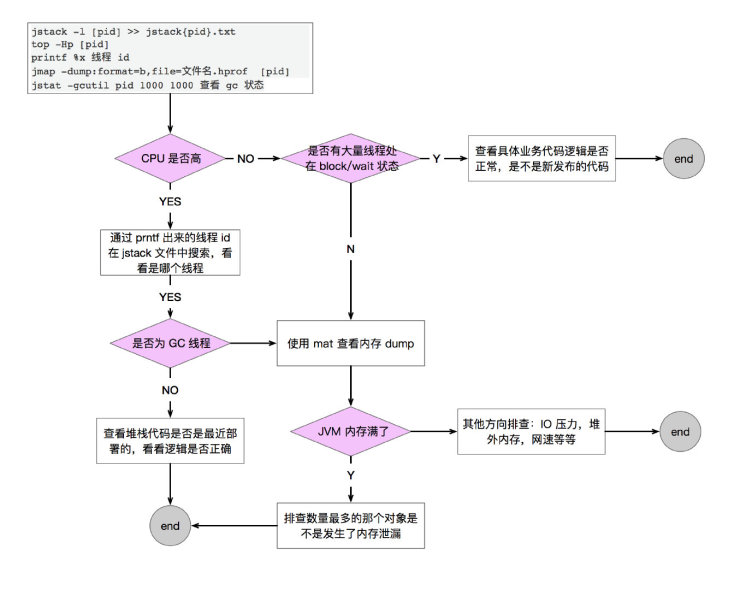
- 系统无响应,长时间无返回,无明显错误日志
没有明显错误且无返回的情况下,说明任务本身没有执行,没有接收到返回,跨系统调用的情况下需检查请求是否发出,response是否丢失以及超时时间设定。在特定应用中,则需特别关注线程栈,使用jstack着重关注锁的情况。常见原因包括线程池满,任务提交未执行/资源池满,超长的锁等待时间/死锁等。 - RT异常增长,无明显错误日志——GC问题/有明显消耗CPU的方法/系统容量不足
在没有明显错误日志的情况下,可优先通过调用链以及监控系统判断是否为依赖的系统RT边长。由于没有明显的错误,着重观察线程栈、CPU消耗以及GC情况。结合系统流量变化判断是否能通过扩容来解决问题。若表现为CPU使用率很高,可以通过CPU火焰图来定位排查。 偶发的数据异常
偶发的数据异常是一种比较难以快速定位的问题。由于是偶发,一般来说有两种可能,一是可能由于并发导致的异常,一种是线上的数据跟跟原先开发时预期的不一样,走到了未曾验证及考虑过的分支。此时可以通过日志中的参数以及Arthas(tt/watch等),抓取异常发生时上下文参数的值来定位判断具体的故障原因。在所有解决故障的手段里面,重启是相对特殊的一种。在面对资源(内存、线程、连接等)泄漏、偶发的死锁或其他并发异常、偶发的组件初始化异常等情况时,重启能够有效缓解此类故障。遇到上述异常情况或者是不能快速定位异常的情况时,可尝试采取重启的办法来解决。特别的,在当前集群负载较高而且没有良好限流熔断措施情况下,不可轻易执行重启。
正文到此结束










