

数据结构基础温故-6.查找(下):哈希表
哈希(散列)技术既是一种存储方法,也是一种查找方法。然而它与线性表、树、图等结构不同的是,前面几种结构,数据元素之间都存在某种逻辑关系,可以用连线图示表示出来,而哈希技术的记录之间不存在什么逻辑关系,它只与关键字有关联。因此,哈希主要是面向查找的存储结构。哈希技术最适合的求解问题是查找与给定值相等的记录。
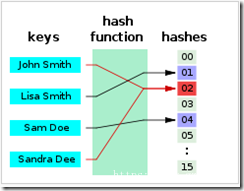
一、基本概念及原理
1.1 哈希定义的引入
这里首先看一个场景:在大多数情况下,数组中的索引并不具有实际的意义,它仅仅表示一个元素在数组中的位置而已,当需要查找某个元素时,往往会使用有实际意义的字段。例如下面一段代码,它使用学生的学号来查找学生的地址。
(1)学生实体类定义
public class StudentInfo { public string Number { get; set; } public string Address { get; set; } public StudentInfo(string number, string address) { Number = number; Address = address; } }
(2)通过索引遍历查找
static StudentInfo[] InitialStudents() { StudentInfo[] arrStudent = { new StudentInfo("200807001","四川达州"), new StudentInfo("200807002","四川成都"), new StudentInfo("200807003","山东青岛"), new StudentInfo("200807004","河南郑州"), new StudentInfo("200807005","江苏徐州") }; return arrStudent; } static void NormalSearch(StudentInfo[] arrStudent, string searchNumber) { bool isFind = false; foreach (var student in arrStudent) { if (student.Number == searchNumber) { isFind = true; Console.WriteLine("Search successfully!{0} address:{1}", searchNumber, student.Address); } } if (!isFind) { Console.WriteLine("Search {0} failed!", searchNumber); } } static void Main(string[] args) { StudentInfo[] arrStudent = InitialStudents(); // 01.普通数组遍历查找 NormalSearch(arrStudent, "200807005"); Console.ReadKey(); }
运行结果如下图所示,可以看到圆满完成了查找任务。

但是,如果查找的记录位于数组的最后或者根本就不存在,仍然需要遍历整个数组。当数组非常巨大时,还以这样的方式查找将会消耗较多的时间。是否有一种方法可以通过学号关键字就能直接地定位到相应的记录?
(3)改写查找方式为哈希查找
通过观察学号记录与索引的对应关系,学号的后三位数组恰好是一组有序数列,如果把每个学生的学号后三位数组抽取出来并减去1,结果刚好可以与数组的索引号一一对应。于是,我们可以将上例改写为如下方式:
static int GetHashCode(string number) { string index = number.Substring(6); return Convert.ToInt32(index) - 1; } static void HashSearch(StudentInfo[] arrStudent, string searchNumber) { Console.WriteLine("{0} address:{1}", searchNumber, arrStudent[GetHashCode(searchNumber)].Address); } static void Main(string[] args) { StudentInfo[] arrStudent = InitialStudents(); HashSearch(arrStudent, "200807005"); HashSearch(arrStudent, "200807001"); Console.ReadKey(); }
可以看出,通过封装GetHashCode()方法,实现了学号与数组索引的一一对应关系,在查找中直接定位到了索引号,避免了遍历操作,从而提高了查询效率,从原来的O(n)提高到了O(1),运行结果如下图所示:
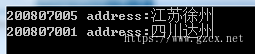
上例中的学号是不重复的,它可以唯一标识学生集合中的每一条记录,这样的字段就被称为key(关键字)。而在记录存储地址和它的关键字之间建立一个确定的对应关系h,使得每个关键字和一个唯一的存储位置相对应。在查找时,只需要根据这个对应关系h,就可以找到所需关键字及其对应的记录,这种查找方式就被称为哈希查找,关键字和存储位置的对应关系可以用函数表示为:
h(key)=存储地址
1.2 构造哈希函数的方法
构造哈希函数的目标在于使哈希地址尽可能均匀地分布在连续的内存单元地址上,以减少发生冲突的可能性,同时使计算尽可能简单以达到尽可能高的时间效率,这里主要看看两个构造哈希函数的方法。
(1)直接地址法
直接地址法取关键字的某个线性函数值为哈希地址,即h(key)=key 或 h(key)=a*key+b
其中,a、b均为常数,这样的散列函数优点就是简单、均匀,也不会产生冲突,但问题是这需要事先知道关键字的分布情况,适合查找表较小且连续的情况。由于这样的限制,在现实应用中,此方法虽然简单,但却并不常用。
(2)除留余数法
除留余数法采用取模运算(%)把关键字除以某个不大于哈希表表长的整数得到的余数作为哈希地址,它也是最常用的构造哈希函数的方法,其形式为:h(key)=key%p
![]()
本方法的关键就在于选择合适的p,p如果选得不好,就可能会容易产生同义词。
PS:根据前辈们的经验,若哈希表表长为m,通常p为小于或等于表长(最好接近m)的最小质数或不包含小于20质因子的合数。
1.3 解决哈希冲突的方法
(1)闭散列法
闭散列法时把所有的元素都存储在哈希表数组中,当发生冲突时,在冲突位置的附近寻找可存放记录的空单元。寻找“下一个”空位的过程则称为探测。上述方法可用如下公式表示为:
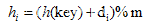
其中,h(key)为哈希函数,m为哈希表长度,di为递增的序列。根据di的不同,又可以分为几种探测方法:线性探测法、二次探测法以及双重散列法。
(2)开散列法
开散列法的常见形式是将所有关键字为同义词的记录存储在一个单链表中。我们称这种表为同义词子表,在散列表中只存储所有同义词子表的头指针。对于关键字集合{12,67,56,16,25,37,22,29,15,47,48,34},我们用前面同样的12为除数,进行除留余数法,可得到如下图所示的结构,此时,已经不存在什么冲突换址的问题,无论有多少个冲突,都只是在当前位置给单链表增加结点的问题。
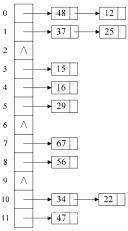
该方法对于可能会造成很多冲突的散列函数来说,提供了绝不会出现找不到地址的保障。当然,这也就带来了查找时需要遍历单链表的性能损耗。在.NET中,链表的各个元素分散于托管堆各处,也会给GC垃圾回收带来压力,影响程序的性能。
二、.NET中的Hashtable
2.1 Hashtable的用法
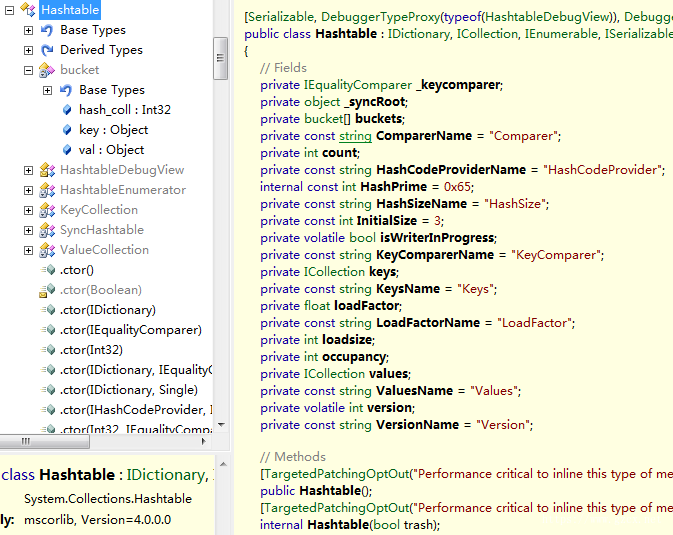
在.NET中,实现了哈希表数据结构的集合类有两个,其中一个就是Hashtable,另一个是泛型版本的Dictionary<TKey,TValue>。这里我们首先看看Hashtable的用法,由于Hashtable中key/value键值对均为object类型,所以Hashtable可以支持任何类型的key/value键值对。
static void HashtableTest() { // 创建一个Hashtable实例 Hashtable ht = new Hashtable(); // 添加key/value键值对 ht.Add("北京", "帝都"); ht.Add("上海", "魔都"); ht.Add("广州", "省会"); ht.Add("深圳", "特区"); // 根据key获取value string capital = (string)ht["北京"]; Console.WriteLine("北京:{0}", capital); Console.WriteLine("--------------------"); // 判断哈希表是否包含特定键,其返回值为true或false Console.WriteLine("包含上海吗?{0}",ht.Contains("上海")); Console.WriteLine("--------------------"); // 移除一个key/value键值对 ht.Remove("深圳"); // 遍历哈希表 foreach (DictionaryEntry de in ht) { Console.WriteLine("{0}:{1}", de.Key, de.Value); } Console.WriteLine("--------------------"); // 移除所有元素 ht.Clear(); // 遍历哈希表 foreach (DictionaryEntry de in ht) { Console.WriteLine("{0}:{1}", de.Key, de.Value); } }
运行结果如下图所示:
2.2 剖析Hashtable
(1)闭散列法
Hashtable内部使用了闭散列法来解决冲突,它通过一个结构体bucket来表示哈希表中的单个元素,这个结构体有三个成员:
private struct bucket { public object key; public object val; public int hash_coll; }
两个object类型(那么必然会涉及到装箱和拆箱操作)的变量,其中key表示键,val表示值,而hash_coll则是一个int类型,它用于表示键所对应的哈希码。众所周知,一个int类型占4个字节(这里主要探讨32位系统中),一个字节又是8位,那么4*8=32位。它的最高位是符号位,当最高位为“0”时,表示是一个正整数,而为“1”时则表示是一个负整数。hash_coll使用最高位表示当前位置是否发生冲突,为“0”时也就是正数时,表示未发生冲突;为“1”时,则表示当前位置存在冲突。之所以专门使用一个标志位用于标注是否发生冲突,主要是为了提高哈希表的运行效率。
(2)双重散列法
Hashtable解决冲突使用了双重散列法,但又与普通的双重散列法不同。它探测地址的方法如下:
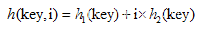
其中,哈希函数h1和h2的公式有如下所示:
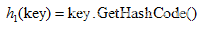
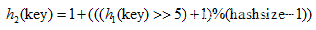
由于使用了二度哈希,最终的h(key,i)的值有可能会大于hashsize,所以需要对h(key,i)进行取模运算,最终计算的哈希地址为:

这里需要注意的是:在bucket结构体中,hash_coll变量存储的是h(key,i)的值而不是最终的哈希地址。

Hashtable通过关键字查找元素时,首先会计算出键的哈希地址,然后通过这个哈希地址直接访问数组的相应位置并对比两个键值,如果相同,则查找成功并返回;如果不同,则根据hash_coll的值来决定下一步操作。
①当hash_coll为0或整数时,表明没有冲突,此时表明查找失败;
②当hash_coll为负数时,表明存在冲突,此时需要通过二度哈希继续计算哈希地址进行查找,如此反复直到找到相应的键值表明查找成功,如果在查找过程中遇到hash_coll为正数或计算二度哈希的次数等于哈希表长度则查找失败。
由此可知,将hash_coll的高位设为冲突检测位主要是为了提高查找速度,避免无意义地多次计算二度哈希的情况。
(3)使用素数实现hashsize
通过查看Hashtable的构造函数,我们可以发现调用了HashHelpers的GetPrime方法生成了一个素数来为hashsize赋值:
public Hashtable(int capacity, float loadFactor) { ....... int num2 = (num > 3.0) ? HashHelpers.GetPrime((int) num) : 3; this.buckets = new bucket[num2]; this.loadsize = (int) (this.loadFactor * num2); ....... }
Hashtable是可以自动扩容的,当以指定长度初始化哈希表或给哈希表扩容时都需要保证哈希表的长度为素数,GetPrime(int min)方法正是用于获取这个素数,参数min表示初步确定的哈希表长度,它返回一个比min大的最合适的素数。
三、.NET中的Dictionary
3.1 Dictionary的用法
Dictionary是泛型版本的哈希表,但和Hashtable之间并非只是简单的泛型和非泛型的区别,两者使用了完全不同的哈希冲突解决办法,我们先来看看Dictionary如何使用。
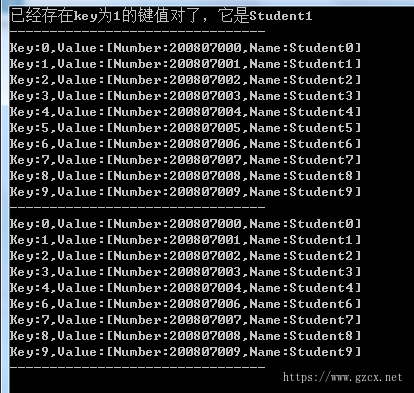
static void DictionaryTest() { Dictionary<string, StudentInfo> dict = new Dictionary<string, StudentInfo>(); for (int i = 0; i < 10; i++) { StudentInfo stu = new StudentInfo() { Number = "200807" + i.ToString().PadLeft(3, '0'), Name = "Student" + i.ToString() }; dict.Add(i.ToString(), stu); } // 判断是否包含某个key if (dict.ContainsKey("1")) { Console.WriteLine("已经存在key为{0}的键值对了,它是{1}", 1, dict["1"].Name); } Console.WriteLine("--------------------------------"); // 遍历键值对 foreach (var de in dict) { Console.WriteLine("Key:{0},Value:[Number:{1},Name:{2}]", de.Key, de.Value.Number, de.Value.Name); } // 移除一个键值对 if(dict.ContainsKey("5")) { dict.Remove("5"); } Console.WriteLine("--------------------------------"); // 遍历键值对 foreach (var de in dict) { Console.WriteLine("Key:{0},Value:[Number:{1},Name:{2}]", de.Key, de.Value.Number, de.Value.Name); } // 清空键值对 dict.Clear(); Console.WriteLine("--------------------------------"); // 遍历键值对 foreach (var de in dict) { Console.WriteLine("Key:{0},Value:[Number:{1},Name:{2}]", de.Key, de.Value.Number, de.Value.Name); } }
运行结果如下图所示:
3.2 剖析Dictionary
(1)较Hashtable简单的哈希地址公式
Dictionary的哈希地址求解方式较Hashtable简单了许多,其计算公式如下所示:

通过查看其源码,在Add方法中验证是否是上面的地址计算方式:
int num = this.comparer.GetHashCode(key) & 0x7fffffff; int index = num % this.buckets.Length;
(2)内部两个数组结合的存储结构
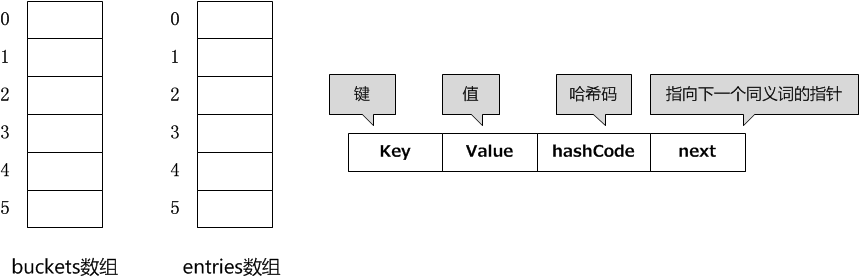
Dictionary内部有两个数组,一个数组名为buckets,用于存放由多个同义词组成的静态链表头指针(链表的第一个元素在数组中的索引号,当它的值为-1时表示此哈希地址不存在元素);另一个数组为entries,它用于存放哈希表中的实际数据,同时这些数据通过next指针构成多个单链表。entries中所存放的是Entry结构体,Entry结构体由4个部分组成,如下所示:
private struct Entry { public int hashCode; public int next; public TKey key; public TValue value; }
Dictionary将多个链表继承于一个顺序表之中进行统一管理:
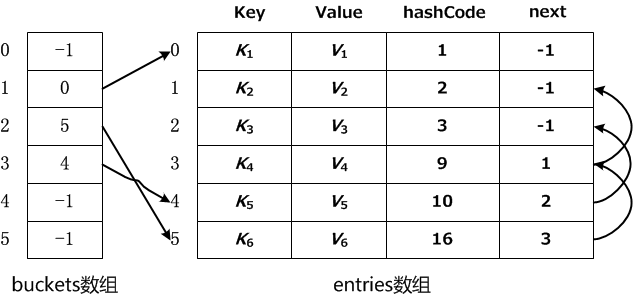
Hashtable 与 Dictionary 的区别:
①Hashtable使用闭散列法来解决冲突,而Dictionary使用开散列法解决冲突;
②Dictionary相对Hashtable来说需要更多的存储空间,但它不会发生二次聚集的情况,并且使用了泛型,相对非泛型可能需要的装箱和拆箱操作,Dictionary的速度更快;
③Hashtable使用了填充因子的概念,而Dictionary则不存在填充因子的概念;
④Hashtable在扩容时由于重新计算哈希地址,会消耗大量时间计算,而Dictionary的扩容相对Hashtable来说更快;
⑤单线程程序中推荐使用Dictionary,而多线程程序中则推荐使用Hashtable。默认的Hashtable允许单线程写入,多线程读取,对Hashtable进一步调用Synchronized()方法可以获得完全线程安全的类型。相反,Dictionary不是线程安全的,必须人为使用lock语句进行保护,效率有所降低。
四、.NET中几种查找表的对比
4.1 测试对比介绍
在.NET中有三种主要的查找表的数据结构,分别是SortedDictionary(前面已经介绍过了,其内部是红黑树数据结构实现)、Hashtable与Dictionary。本次测试会首先创建一个100万个随机排列整数的数组,然后将数组中的数字依次插入三种数据结构中,最后从三种数据结构中删除所有数据,每个操作分别计算耗费时间(这里计算操作使用了老赵的CodeTimer类实现性能计数)。
(1)准备工作:初始化一个100万个随机数的数组
int length = 1000000; int[] arrNumber = new int[length]; // 首先生成有序数组进行初始化 for (int i = 0; i < length; i++) { arrNumber[i] = i; } Random rand = new Random(); // 随机将数组中的数字打乱顺序 for (int i = 0; i < length; i++) { int randIndex = rand.Next(i,length); // 交换两个数字 int temp = arrNumber[i]; arrNumber[i] = arrNumber[randIndex]; arrNumber[randIndex] = temp; }
(2)测试SortedDictionary
// Test1:SortedDictionary类型测试 SortedDictionary<int, int> sd = new SortedDictionary<int, int>(); Console.WriteLine("SortedDictionary插入测试开始:"); CodeTimer.Time("SortedDictionary_Insert_Test", 1, () => { for (int i = 0; i < length; i++) { sd.Add(arrNumber[i], arrNumber[i]); } }); Console.WriteLine("SortedDictionary插入测试结束;"); Console.WriteLine("-----------------------------"); Console.WriteLine("SortedDictionary删除测试开始:"); CodeTimer.Time("SortedDictionary_Delete_Test", 1, () => { for (int i = 0; i < length; i++) { sd.Remove(arrNumber[i]); } }); Console.WriteLine("SortedDictionary删除测试结束;"); Console.WriteLine("-----------------------------");
(3)测试Hashtable
// Test2:Hashtable类型测试 Hashtable ht = new Hashtable(); Console.WriteLine("Hashtable插入测试开始:"); CodeTimer.Time("Hashtable_Insert_Test", 1, () => { for (int i = 0; i < length; i++) { ht.Add(arrNumber[i], arrNumber[i]); } }); Console.WriteLine("Hashtable插入测试结束;"); Console.WriteLine("-----------------------------"); Console.WriteLine("Hashtable删除测试开始:"); CodeTimer.Time("Hashtable_Delete_Test", 1, () => { for (int i = 0; i < length; i++) { ht.Remove(arrNumber[i]); } }); Console.WriteLine("Hashtable删除测试结束;"); Console.WriteLine("-----------------------------");
(4)测试Dictionary
// Test3:Dictionary类型测试 Dictionary<int, int> dict = new Dictionary<int, int>(); Console.WriteLine("Dictionary插入测试开始:"); CodeTimer.Time("Dictionary_Insert_Test", 1, () => { for (int i = 0; i < length; i++) { dict.Add(arrNumber[i], arrNumber[i]); } }); Console.WriteLine("Dictionary插入测试结束;"); Console.WriteLine("-----------------------------"); Console.WriteLine("Dictionary删除测试开始:"); CodeTimer.Time("Dictionary_Delete_Test", 1, () => { for (int i = 0; i < length; i++) { dict.Remove(arrNumber[i]); } }); Console.WriteLine("Dictionary删除测试结束;"); Console.WriteLine("-----------------------------");
4.2 测试对比结果
(1)SortedDictionary测试结果:
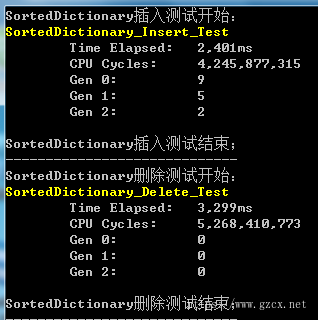
SortedDictionary内部是红黑树结构,在插入和删除操作时需要经过大量的旋转操作来维持平衡,因此耗时是三种类型中最多的。此外,在插入过程中,引起了GC大量的垃圾回收操作。
(2)Hashtable测试结果:
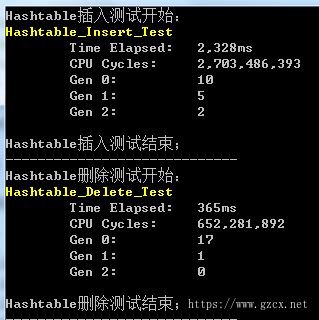
Hashtable插入操作的耗时和SortedDictionary相近,但删除操作却比SortedDictionary快了好几倍。
(3)Dictionary测试结果:
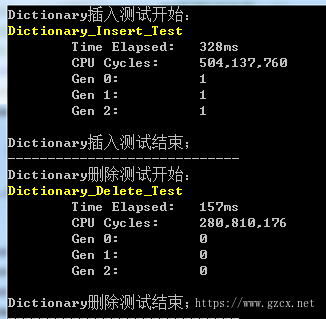
Dictionary在插入和删除操作上是三种类型中最快的,且对GC的友好程度上也较前两种类型好很多。
参考资料
(1)陈广,《数据结构(C#语言描述)》
(2)程杰,《大话数据结构》
(3)段恩泽,《数据结构(C#语言版)》
(4)马语者,《C#中Hashtable的用法》











